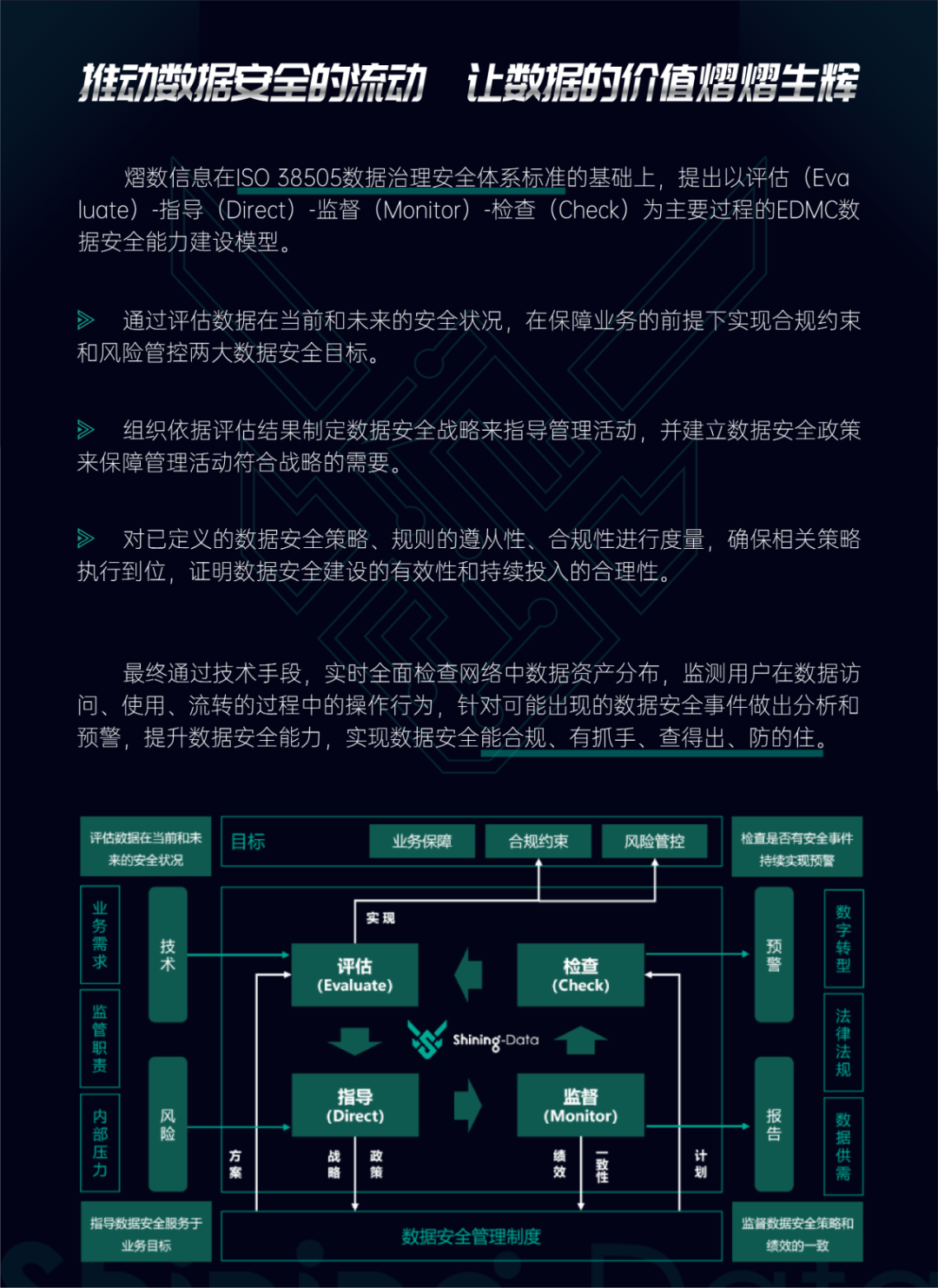
安全419了解到,全国信息安全标准化技术委员会秘书处近日发布了国家标准《信息安全技术 网络数据分类分级要求》征求意见稿(以下简称《要求》),给出了数据分类分级的基本原则、框架和方法等。
作为开展工作的基本前提,数据分类分级是所有涉及数据处理活动的企业都绕不开的一大步骤,也是当前数据安全建设的难点所在。
一方面,数据分类分级是合规刚需。
网安法提出“国家实行等级保护制度”,其中“采取数据分类、重要数据备份和加密等措施”被列为细则要求之一,要求网络运营者履行安全保护义务,防止网络或者被窃取、篡改。
数安法明确“国家建立数据分类分级保护制度”,并进一步要求各地区、各部门按照数据分类分级保护制度,确定本地区、本部门以及相关行业、领域的重要数据具体目录,对列入目录的数据进行重点保护。
个保法提出个人信息处理者应采取措施防止未经授权的访问以及个人信息泄露、篡改、丢失,其中相关措施中明确提出“对个人信息实行分类管理”。
另一方面,数据分类分级是数据安全的起点。
由于不同类型的数据,其级别和价值均不同,不能等同视之,应根据数据的重要性、价值指数,予以区别对待。实行数据分类分级是保障数据安全的前提,在管理和技术层面起到承上启下的关键作用。企业依托数据分类分级在运维制度、保障措施、岗位职责等多个方面进行针对性编制,可强化体系落地执行性;而根据不同数据级别进行不同安全防护,将最大限度实现细粒度的管控保护和开发利用平衡。
在安全419今年推出的《数据分类分级解决方案》系列访谈中,受访的数据安全厂商普遍表示,缺乏明确的规范性和指引性的政策文件,来指导不同行业及不同规模的企业流程化地开展工作,是数据分类分级实施中最突出的痛点。《要求》的出台,将为企业落地提供详细指引和参考。
根据《要求》,数据分类时,按照先行业领域分类、再业务属性分类的思路进行。行业领域开展数据分类时,应根据行业领域数据管理和使用需求,结合本行业本领域已有的数据分类基础,灵活选择业务属性将数据逐级细化分类。
数据分类流程主要包括以下步骤:
确定数据处理者业务涉及的行业领域;
按照业务所属行业领域的数据分类规则,对该业务运营过程中收集和产生的数据进行分类;
识别是否存在法律法规或主管监管部门有专门管理要求的数据类别(如个人信息),对个人信息、敏感个人信息进行区分标识;
如果存在行业领域数据分类规则未覆盖的数据类型,可以从组织经营角度结合自身数据管理和使用需要对数据进行分类。
《要求》明确,数据分级时,根据数据在经济社会发展中的重要程度,以及一旦遭到泄露、篡改、破坏或者非法获取、非法利用,对国家安全、公共利益或者个人、组织合法权益造成的危害程度,从高到低分为核心、重要、一般三个级别。通过定量与定性相结合的方式,综合确定数据级别。
可参考以下步骤开展数据分级:
确定分级对象:确定待分级的数据,如数据项、数据集、衍生数据、跨行业领域数据等;
分级要素识别:影响数据分级的要素,包括数据领域、群体、区域、安全风险等,以上属于定性要素,同时还包括精度、规模、覆盖度等定量要素,以及深度通常作为衍生数据的分级要素;
数据影响分析:结合数据分级要素识别情况,分析数据一旦遭到泄露、篡改、破坏或者非法获取、非法利用、非法共享,可能影响的对象和影响程度;
综合确定级别:在上述基础上,首先进行重要数据定级评估,重点评估数据是否可能直接危害国家安全、经济运行、社会稳定、公共健康和安全;核心数据定级评估可在识别为重要数据的基础上,重点评估数据是否可能直接影响政治安全、国家安全重点领域、国民经济命脉、重要民生、重大公共利益;重要数据、核心数据之外的数据可确定为一般数据。
数据安全厂商熠数信息CTO方伟在接受安全419采访时总结,行业监管机构必须在本行业里推进这项工作,并提出更具体细致的分类方法,目前金融、电信等领域已经有了该行业数据分类的具体标准,其他行业也需要加快步伐。
与此同时,企事业单位也要身先士卒,配合行业监管机构,参与到本行业数据分类分级的工作中,不能只等着行业下发标准要求,而是通过自身实操,给行业监管提供最佳实践,才能推动数据分类分级更好的落地。
《要求》为企业提供了分类分级的方法和实施流程,下一步,企业将面临如何把政策要求转换为内部的组织架构和管理制度,自研或选择安全工具效落实数据分类分级政策和公司管理制度的问题。
方伟对此强调,《要求》中指出数据分类分级要依据业务属性,例如:业务领域、上下游环节、数据主题、数据用途等对数据进行细化,这也恰恰是企业落地的最难点,安全部门通常并不了解业务,这就导致工作无法开展,进而造成数据分类分级无法落地。因此,在第一步建立组织保障时,不仅需要领导负责统筹和决策,更重要的是明确业务部门,而不是安全部门是数据分类分级工作的主导部门。
“很多企业在进行数据分类分级时,认为这是一种服务,是人工进行的,但事实并非如此。”方伟进一步指出,“数据分类分级在很多情况下需要人工和产品相结合的方式进行,人工服务是在数据分类时增加业务属性,提供上下游环节,分类能更加准确。当数据达到一定体量后,就可以通过标签体系实现自动化,消除人为干预的风险,降低人工分类分级的成本,同时可以保证数据实时的、全量的处理,避免出现数据分类分级的孤岛。”
此外,数据分类分级的场景较为固定,存在可量化的行业逻辑,通过知识图谱技术能够在抽取信息时形成结构化的知识,先定义本体和数据规范,再抽取数据,形成“自顶向下型”知识建模,能够更好地实现自动化数据分类分级。
上规模的组织往往拥有多个业务系统并且系统之间存在复杂的关联关系,做好数据分级分类是一个较长期的工作,需要有前期梳理准备和总体规划,并且需要有专业团队和技术工具的协助。
据方伟介绍,熠数信息将多源异构的数据利用知识图谱实现动态扩充变迁的能力,定义数据的属性以及数据之间的关联,就可以把原来分散在各个地方的数据经过抽取、融合、链接形成基于行业和业务特点的知识图谱,通过内置规则,自动发现组织内的暗数据、新数据和敏感数据,从而减少人力投入成本,实现准确快捷的分类。
此外,在分级管理时,则综合了局部或全局信息的特征模型。分级的设定不再是单一的数值,而是类似根据数据的值域分级中涉及的多个数据资源对象。例如,按照账户对不同数据资源的访问量进行汇总,对使用频率高的资源设定更高等级,从而加强备份或其他安全管理,这样能更好的实现分级管理。
同时需要明确的是,数据分类分级往往不是独立的,需要和敏感数据发现、数据风险评估等工作结合在一起,其分类分级的结果也正是后续指导数据安全建设以及数据业务开发利用的基础,企业应当正确认识其综合价值和必要性。当前,数据分类分级工具与成熟的数据安全产品进行联动联防,践行一致性的安全策略,让一体化的平台方案逐渐成为行业主流,最终是为了在满足合规和安全的前提下,让数据得以高效利用,让数据的价值充分发挥。